
AIDST has quickly established itself as one of the most important finance based data science conferences in the calendar. I recently attended and presented at the recent AIDST London event in September. The conference featured a mixture of both high-level talks and also more technical sessions.
The conference began with a presentation from Manoj Saxena, currently at AI Global and formerly the head of IBM Watson. He noted that AI was like another revolution for automation, in the same way that the Internet had connected or “webified” the world. However, these AI systems could be opaque. There had to be a way to understand the decision making process behind them. Furthermore, such systems needed to be fair and unbiased. Their complexity meant that it was difficult for humans to oversee AI systems alone. Hence, whilst AI systems might bring many benefits, they also brought their own risks. He suggested a solution could be an AI risk scanner, essentially, an AI based system which could help oversee other models. These risk scanners could be seen as part of “trust as service” when it came to AI, making a parallel with the way the https protocol is used to secure the web.
The concept of trust in AI was also taken up by Afsheen Afshar. Even amongst industry leaders, there were disagreements about the dangers of AI, with Afshar citing the opposing views of Mark Zuckerberg and Elon Musk on the subject. He gave an illustration of situations where machine learning which underpins AI can lose the trust of users. For example, if the training/validation data totally differs from test data, AI is untrustable. Similarly, if test data violated structural assumptions of a model it could render AI untrustable. He gave several examples, such as a self-driving car, which encounters situations never seen before (which are therefore not within its training set).

Expanding on the theme of bias, was a panel moderated by Anthony Ledford, chief scientist at AHL part of Man Group. The panellists gave many potential examples of bias that could sometimes be observed in finance, when using machine learning. They ranged from trading strategies which would simply learn to stay long, essentially replicating passive strategies, to incorrectly learning seasonality from news, because a certain quarter happened to have a lot of bad news. It was possible to learn things which weren’t “real”. Later in the day, I attended one of the highlights of the whole conference, a session with Jonathan Guthrie from the FT, interviewing Sandy Ratray CIO of Man Group. Their discussion gave some real insights into the world of systematic fund management.

The basis of the whole investing industry is essentially trade idea generation. How do quant researchers find ideas? Marcos Lopez de Prado noted in his talk that it wasn’t simply a matter of waiting for inspiration. He cited the example of laboratories, which have a factory driven process approach to creativity. He suggested that it was possible to adopt a similar systematic approach to creativity in finance. The old model for finance was that a fund would hire teams of data scientists. These teams would work in silos, without sharing IP or resources. Lopez de Prado argued that such an approach needed to change. There are so many datasets today and potential ways to analyze problems, that it was necessarily to have a much more collaborative approach in finance, which needed massive scale. He gave examples of how such research could be crowdsourced, giving several different approaches of how this problem could be tackled.

Perhaps unsurprisingly, alternative data was a key theme of the conference, and there were numerous sessions on the topic. Chris Camillo, an independent trader and formally one of the founders of TickerTags explained how to use social media as a way to gain insight into consumer behavior. Gene Ekster delved into some of the technical and practical issues associated with alternative data and how to evaluate such datasets. A panel brought together Chris and Gene, alongside Bryan Yates from Orbital Insights and Lisa Schirf formally of Citadel to take a look at the future for alternative data. They raised some of the challenges which had to be overcome when using alternative data, such as the necessity to do entity mapping and also structuring the data. They also touched on some the legal questions associated with alternative data, such as the recent LinkedIn ruling which is likely to be beneficial for data vendors of web sourced data. I also presented The Book of Alternative Data alongside my fellow co-author Alex Denev, which summarized many of the same points raised in the panel, as well as looking at some use cases from several different areas such as satellite imagery and news.
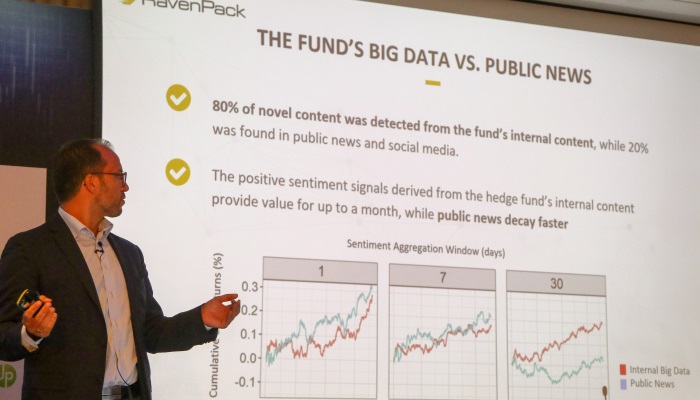
However, alternative data isn’t always something external to your organization. Peter Hafez from RavenPack presented a case study which his firm had undertaken with an asset manager to understand the value of their internal data using NLP. They ingested a number of internal sources including e-mail and other analyst generated content. They found that in general, there was more novel content in their own internal data compared to public news data. Furthermore, there was also less alpha decay in internal only data, compared to public sources. Sticking with the topic of NLP, Mike Chen from PanAgora, gave a technical talk on trying to understand Chinese cyberslang in order to understand sentiment for Chinese stocks, which is heavily retail driven. He noted some of the challenges with doing NLP in Chinese, notably the number of characters, which renders a traditional bag of words approach tricky. Instead, more complicated word embeddings were applied as part of the process. Also, on the technical side was Gary Kazantsev’s talk on the advances of machine learning. He discussed some of the difficulties with analyzing financial time series, notably, the fact that they are non-stationary. There can also be non-linear interactions between various time series, as well many different timescales. He noted though that finance wasn’t unique, pointing out that ecological time series often share similar characteristics with financial time series, which I hadn’t realized before.

The difficulty with data is that it doesn’t tell you about the data you don’t have, which is essentially a blind spot. In sense it was the case of unknown unknowns to coin Donald Rumsfeld’s terminology. Professor David Hand’s talk was based around this topic and his new book “Dark Data” to be published next year, which I’m very much looking forward to reading. He gave numerous examples which were related to incomplete data, ranging from medicine to finance, showing how lack of data and incorrect assumptions can introduce bias.
It will be interesting to see what will be discussed at the next installment of AIDST in March 2020. What is very clear, is that there is still a lot of work to be done in this field and I’m looking forward to attending future AIDST conferences!
This article was kindly sponsored by Alpha Events. The next edition of AI Data Science in Trading will be in New York 16-18 March 2020. See
https://www.aidatatrading.com for more tickets and details of the next conference.