
Think of Barcelona and there are several images which might come to mind. Perhaps it is Messi cleaning up against Barca’s opposition (yes, that was intended to be a pun!). Maybe it is Antonio Gaudi, his buildings illuminating the city from the (still unfinished) Sagrada Familia to the Casa Batllo. Indeed, it could be sound of Freddie Mercury and Montserrat Caballé musing about this enchanting city, in the anthem for the Barcelona Olympics over 25 years ago. For one week only this May, it was also the city of quants attending the annual Global Derivatives conference (agenda here). In recent years, the event has somewhat morphed from an affair purely dominated by discussions between pricing quants to a broader event, encompassing the many areas of quant finance which are present in our industry, which include risk management, regulation and trading. Indeed, it is no longer the case, that a quant in a bank will purely be found in option pricing roles. Over several days, I participated in the event as a presenter, moderator and attendee. Most of the talks, I attended were skewed towards trading and strategies, given my background. However, I also made time to see some of the more “traditionally quanty” talks on pricing and valuation adjustments. Here are my general takeaways from the event.
Smart beta, portable alpha, games, liquidity, term premium etc.

Arthur Berd moderating the smart beta panel
The event began with the buy side and quant tech day. Among, the many highlights of the initial day was a discussion on active vs passive vs smart beta. It was noted by Arthur Berd, from General Quantitative, that it is difficult to classify any investor as passive: after all, even passive investors will face margin calls. Even the terminology of smart beta caused some debate, with the quip that perhaps it was “dumb alpha”. It was suggested that whilst many components of smart beta might have exhibited long term performance (such as the value factor) and are based on common ideas, trying for example to weight them based on recent performance is unlikely to be successful. The ability to withstand drawdowns in specific strategies was necessary to be able to realise the long term success of such approaches. Andrea Alberto Castaldi (Whitehaven) noted that a multi-factor approach makes sense, however, as ever the key was the implementation of such a model. This idea of a long term robustness in the underlying factors came up several times. It was noted that in general complicated or baffling terminology seemed to be overused by those in finance. Even the term smart beta was a rebrand of something which pre-crisis had sometimes come under the umbrella of “portable alpha” pre-crisis, noted Richard Martin (Apollo). The fee compression seen in such products might result not so much in the “best” surviving, it was suggested, but more those who are able to withstand the lower fee structure. A key issue for market participants whether they are active or passive or smart beta is of course, the concept of liquidity which was the subject of Rick Lacaille’s talk (State Street Global Advisors). Rick explained that liquidity risk extends across many different facets. There is the most obvious question of how much it costs to transacts in the market and how deep the liquidity risk. There is also the related issue of how to deal with inflows and outflows, in particular, what assets can be sold to come up with cash.
Following on from the theme of smart beta and factor based investing, was Julius Baer’s Arthur Sepp, who discussed approaches to filtering such strategies, like carry, vol selling and trend. Whilst these strategies might generate the returns, the key is in managing drawdowns. For example, typically during periods of high vol, carry and short vol strategies are likely to suffer. However, typically, trend does better when vol picks up. He used a regime classification approach using a Markov chain, to try to see when the best periods would be for the underlying factors. Arta Babaee also discussed a similar topic, addressing how to identify risk on/risk off periods in markets using ideas from digital signal processing, by attempting isolate different frequencies from time series. He noted how trend following tends to capture a certain frequency in time series data. His work on MAFI (multi-asset fragility indicator) can be found on SSRN.

Mihail Turlakov on Kelly’s criterion
One of the key questions when allocating, whether it is passive or active, is the leverage employed in an investment. Mihail Turlakov (Sberbank) discussed investing in the context of the Kelly criterion, which gives guidelines on how to leverage an allocation. He noted the various forms of uncertainty an investor faces. One source is genuine unpredictability, tail risk style events, which we might wish to define as Black Swan events. Then there is the uncertainly which stemmed from other intentions of other investors. He suggested that the Kelly criterion, tended to result in heavily concentrated portfolios. If you are confident of your edge, then it might make sense to leverage. However, such an approach might be fragile when we are faced with tail risk events. Indeed, it is a tricky balance to make. We want to allocate enough to a “winning” trade but at the same time need to protect against the downside.
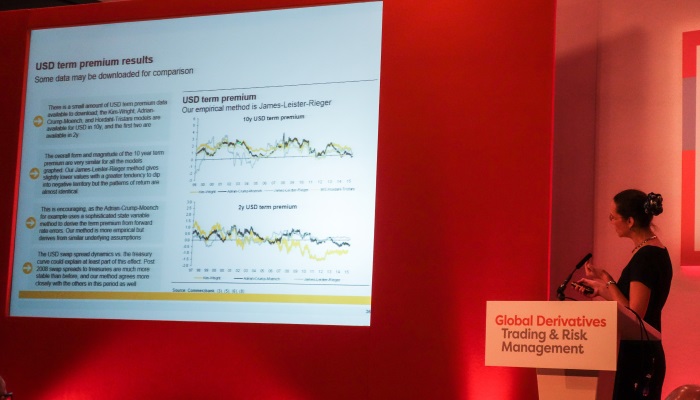
Jessica James on term premium in rates
An important feature of fixed income markets is the concept of the term premium and also whether interest rate forwards give us an element of predictability. She noted that interest rate forwards did offer some predictability when they were pointing to lower yields Term premium itself can be tricky to model, even if the definition seems simple, namely the difference between rate expectations and the observable yield. Jessica James (Commerzbank) discussed an empirical approach to working it out, namely looking at the forward rate error, as a way of observing this premium. Whilst the calculation is typically relatively simple compared to other modelling approaches, it does of course rely upon us observing the yield, hence, we can only do this retrospectively, once we have sufficient data. James showed how the results were comparable with other models for the term premium. The parallel in vol space to term premium or forward rate error would be the volatility risk premium, the difference between expectations (implied vol) and actual (realised vol). Peter Carr (NYU) discussed volatility, skew and smile trading in this context, with the motivating question, what’s the best trading strategy when we have a view about implied vs realised vol.
CVA, FVA and all that, the future of quants?

Damiano Brigo on the changing times for quants
Once upon a time, pricing an option whether that of a vanilla or some hideously complicated exotic, involved actually pricing an option. However, following the financial crisis, it became apparent that perhaps it wasn’t all that “simple”. Damiano Brigo explored how the market had changed in that aspect. Whilst, the market might be trading fewer exotics, and focusing more on vanillas, the various pricing adjustments being made are becoming increasing more complicated. Take for example the idea of CVA, a credit value adjustment to take into account the credit worthiness of a counterparty. Increasingly there is what is slowly becoming an alphabet soup of these adjustments (DVA, FVA, XVA and KVA?) – where exactly will it stop, asked Brigo? There is also the difficulty in whether these adjustments are done in a linear or non-linear way. If they are done a non-linear way, it is difficult to know how different areas of the bank understand where their responsibilities start and end. Brigo suggested that rather than ever increasing complexity, why not have a charge to the client? From a quant’s point of view, all these pricing adjustments provide many computational challenges, and have resulted in the adoption of GPUs and other more specialised hardware (and a lot of extra work for quants!)

John Hull on the future of quant finance
Brigo also hosted a panel discussing the future of quant finance with panelists from academia, the buy and sell sides: John Hull (University of Toronto), Matthew Sargaison (AHL) and Jesper Andreasen (Danske). The discussion followed on naturally from Brigo’s presentation about the changing nature of the quant world with respect to valuation. Hull agreed that the quant world had changed. In the past, it was the case that quants worked on PDEs etc. However, 10-15 years from now, he expected quants to be working on very different projects. Whereas in the past, banks hired mainly from maths and physics backgrounds, they are now increasingly looking towards computer science. It was necessary for quants to improve their skill set continually to handle changes. Sargaison echoed these points, suggesting that it was not possible to have your mind fixed in a single idea. It was important to have curiosity towards problems. The need for strong computing skills was increasingly pitting companies such as AHL against Google and Facebook for talent. There was also a question from the audience about the disappointment some new graduates felt after they worked in industry. The panel noted that it was never the case that every single part of a job might be enjoyable. Importantly, it was also necessary for newcomers to be realistic about what an entry level job entailed. Indeed, this is something that I can relate to, in my own career. It takes time to build up knowledge and to take more responsibility. Before the quant finance panel, a somewhat more unusual presentation for a quant conference was given by Daniel Tammet, a writer, which was entitled “Perceiving the world differently”, through the lens of his autism. In particular, he noted how his senses very often blended together, and a such he often visualised numbers through image and colour. Indeed, this ability helped him to memorise the number pi to thousands of decimal places. It was a somewhat refreshing way to thing about numbers for an audience full of quants.
Special events, Brexit and market pricing and dubious statistics
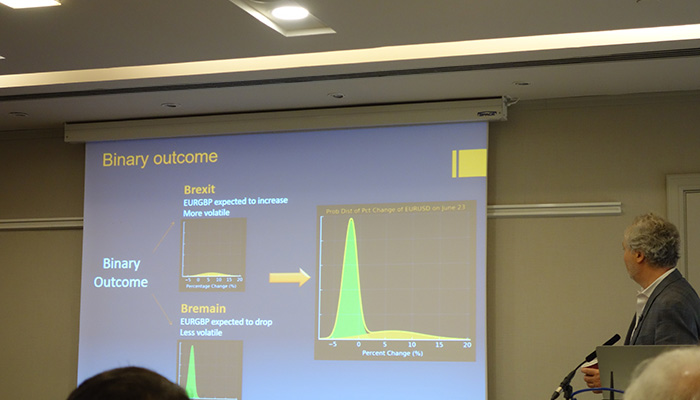
Dupire discussing extracting market expectations from vol surfaces around events
Bruno Dupire (Bloomberg) gave a presentation on special events and understanding market pricing of them from the vol market. Indeed this is also an area, where Iain Clark (Efficient Frontier Consulting) and myself have done a lot of work in particular around Brexit (SSRN paper here). He discussed how over scheduled special events such as Brexit, we can extract probabilities of outcomes from FX vol surfaces and also estimate distributions for the price action following the event. Understanding the potential ranges of outcomes provides important information for traders, even if the actual outcome (was it going to be a leave or remain vote over Brexit?) is tricky to predict. After all, having an understanding of the potential risk/reward of a trade is key to taking any trading decision.

John Hulsman speaking about the world order
On the topic of Brexit and also Trump more broadly and the broader political outlook, John Hulsman gave a talk. He suggested that a large part of the reason analysts and journalists failed to spot both Brexit and Trump, was what he called the “Davos syndrome” of getting to close to their subjects, which skewed their analysis. Whilst I have some sympathy with this idea, it is not clear whether even “leave” campaigners believed they were going to win beforehand. In retrospect, it all of course seems obvious. He also tried to draw the analogy between the world order and the Beatles and the Rolling Stones. Whereas the Rolling Stones, always seemed like the band who would break up, they have somehow managed to stick together for decades, despite the internal fractures within. This contrasts to the Beatles, where tensions led to their breakup in 1970 after less than a decade. He suggested that the current life cycle of the world order which began post-WWII, was around the phase where the Beatles were during their White Album in the late-1960. In other words, still holding together, but increasingly being pulled apart in different directions. On the subject of Trump, he noted that he was not beholden to the establishment. He was however indebted to what he termed Springsteen Democrats, and it was this group that he needed to keep on board.

David Spiegelhalter on informing with statistics (as opposed to misinforming)
A big part of the Brexit campaign, there was the claim of 350mn GBP per week which would be spent on the NHS if the UK exited EU. In David Spiegelhalter’s talk he gave this example of the use of statistics and many others which had been used by the press and politicians to persuade rather than inform. His talk was about the misuse of statistics when communicating the public. One of his major roles was to find ways to combat such misuse of statistics and the use of statistics to misinform. He stressed that it was a right for everyone to receive statistics which were objective and understandable. He noted that one of the most dubious practices was the quotation of relative probabilities. He also talked about the misuse of axes labels. Indeed, on financial Twitter accounts, the hashtag of #chartcrime has come about, specifically to flag these types of analysis, which often include unusual scaling on plots, to exaggerate very small changes in statistics, in order to justify a view, rather than to inform.
Machine learning, Big Data and programming languages

Big Data panel with (left to right) Tyler Ward (Google), Matthew Dixon (IIT/Thalesians), Pierce Crosby (StockTwits) and Manlio Trovato (Lloyds)
I’m not sure if there is “Richter style” scale for buzzwords, but if there is one, I suspect both “machine learning” and “Big Data” would lie somewhere near the top of scale. There were several talks and panels devoted to these areas from different view points. The panel on Big Data chaired by Pierce Crosby (StockTwits) explored the use of Big Data within finance from several viewpoints. Obviously, the key to Big Data is the “data” part! Matthew Dixon discussed how at very high frequencies, you had to deal with issues such as dropped network packets and also timing problems. Manlio Trovato (Lloyds) had a different perspective when it came to data, given that Lloyds is a major commercial bank. Not only did they store large amounts of market data, but also dealt with data relating to their commercial and personal banking customers. As a result, the problems could vary widely, and could for example be related to providing better customer experiences, as opposed to purely aiding their trading function. Tyler Ward from Google and also an alumnus from Wall Street in mortgages, noted that a lot of the work done at Google involves large scale map reduce functions. He said that whilst the algorithms hadn’t changed much for machine learning, the crucial difference now, was the abundance of data and also computation power. Matthew Dixon echoed this point, noting the need to invest in the right hardware, and at the same time, noting that a large number of grad students were now coming to industry with training in data science. He also made points relating to how Python was taking the lead when it came to machine learning libraries, against R.

On stage discussing how to use Python to analyse market data
On the subject of computing languages, I moderated a panel discussing the question of which (programming) language should quants speak? The panelists were Jesper Andreasen (Danske), Jan Novonty (HSBC) and Paul Bilokon (Thalesians). The panel started with each panelist discussing their chosen language (C++, q and Java respectively). However, later, much of the discussion centred around the idea that there was no “perfect” language. Instead, it was very much a case of picking a language which suited the problem which was being solved. For example, for Andreasen, C++ suited his needs, given its. Furthermore, he did not to do rapid prototyping for the types of problems he need to solve. Indeed, in such a scenario, he noted Python might be a good choice, when it is necessary to explore many ideas quickly. Keeping to the Python theme, I also gave a talk on its use in finance. I discussed the Python ecosystem which is very rich for analysing data. Later, I gave some demonstrations of my own open source Python libraries, showing how they could be used to quickly prototype trading strategies.

Matthew Dixon discussing various deep learning architectures
Matthew Dixon also gave a practical use case for machine learning in developing trading strategies around the order book, which included modelling the various levels of the order book, which would be useful for market makers. He began by explaining the concept of deep learning. The idea is of deep learning is to use hierarchical layer of abstraction to represent high dimensional nonlinear predictors. He discussed questions such as: how often you should train such a model and what type of loss function could be used to determine how “good” the training is. He noted that the model he presented was typically far better a predicting very short term moves, for example at tick level than it is much further out. In a sense, this seems reasonable, given that at a very low level, a lot of the price action can be impacted significantly by market microstructure style behaviour. This contrasts to longer term time horizons, when many other factors might come into play, which tend to be much slower moving, such as the fundamentals of a stock. Nicholas Salmon from JPM also addressed a similar area discussing how machine learning could be used for execution algorithms, to beat benchmarks such as VWAP. Bruno Dupire gave an introductory talk on machine learning, an area which he explored in his academic career. An interesting point which was made several times in the conference was that many of the techniques associated with machine learning are not especially “new” and some have been around for decades. The difference now is the abundance of data and relatively cheap computing power, echoing some of the discussion from the Big Data panel.

Paul Bilokon on why finance is difficult for machine learning compared to other areas
Paul Bilokon (Thalesians) and Jan Novotny (HSBC) discussed machine learning and how to implement it in the q language (in kdb). Bilokon noted that the problem of machine learning was somewhat different to our areas, given the amount of noise that is present in financial data. If we take the example of facial recognition, where machine learning has been successful, the problem is relatively static (a face does not change significantly unless we look over a very long period). This contrast to markets, which are continually evolving. On the subject of kdb, it is often thought of purely as a very fast columnar database (some of which is in memory). Despite this its q language is remarkably powerful. Hence, it is possible to do a large amount of analytics within the database rather than shifting the data outside and then analysing it, for which there is some overhead. In the presentation, they introduced the area of machine learning, and also gave some practical examples of machine learning algorithms in q including nearer neighbours, which were taken from their forthcoming book on kdb, due out on Wiley in 2018.
Taking a very different tack, there was a presentation from Grigorios Papamanousakis from Aberdeen Asset Management, who examined using machine learning in an asset allocation context, somewhat different to the lower level implementations related to tick data. In his study he noted that the key, was the question asked in machine learning. When using market factors in such a model, we needs to be sure that they were comprehensive, explainable, persistent and explainable. Indeed, I would argue this is necessary for any sort of market model, whether or not we are applying machine learning. The idea of his approach was to discover the relationships between economic events and market performance (as opposed to trying to tie in the historical performance of model, with its future performance). Of course such an approach requires a deep understanding of the market, and is not so much a question of pure data crunching. On the subject of Big Data, Svetlana Borovkova, gave a presentation on the use of news data to model systematic risk. Her approach was to use structured news data collected by Thomson Reuters on SIFIs (systemically important financial institutions) and construct indices around them to understand market wide risks.
My general impression from most of the presentations and many of the conversations I had throughout the conference was that whilst machine learning was an interesting concept for traders, most are still exploring the area. We are simply not at the stage where market participants are actively taking large amounts of risk related to a machine learning. There is also likely to be a lot of room for adopting of alternative data/unusual datasets more broadly in the finance community. Whilst large quant funds are very much using this data in a lot of their research, this is less the case with the discretionary community.
Conclusion
Generally speaking, the feeling among quants at the conference was fairly upbeat about the industry, and that there is likely to be a lot of work ahead for quants in the coming years. Of course, the nature of what many quants do has changed over the years, however, this is part of the challenge! The key for quants will of course will be to adapt to changes in the industry with updated skills. The emergence of machine learning as a topic of conversation during the breaks and at the event is perhaps a testament to this changing dynamic in what . At the same time, more traditional areas such as pricing continue to evolve with concepts like CVA and FVA. Hopefully see you at Global Derivatives 2018 in Lisbon, which is scheduled for May 14-18.
This article was kindly sponsored by Global Derivatives. Download all the photos I took at Global Derivatives from Flickr at https://flic.kr/s/aHskVttqJq