
The above photo is of Montjuïc Castle which has one of the best views over the city. The view from there kind of explains why the location was chosen from a strategic perspective. As a city Barcelona has many places which punctuate the skyline, whether it’s that castle, or the (still unfinished) Sagrada Familla, Gaudi’s masterpiece. One of the newer additions to the skyline is the Hotel Arts, taking its place by the sea. It was there that QuantMinds took place last week. I have to admit it seemed somewhat of a novelty to present to a real life audience again, as opposed to a Zoom screen. Of course, thoughts of covid were omnipresent during my trip, but for the most part, the conference actually felt far more normal than I would have expected. What follows are a few of my takeaways from what was presented at QuantMinds (and if you’re interested, it is possible to view recordings from some of the talks online with a digital pass). Obviously, it’ll only be a limited snapshot, given that covering every talk I had attended would make this article several times longer!

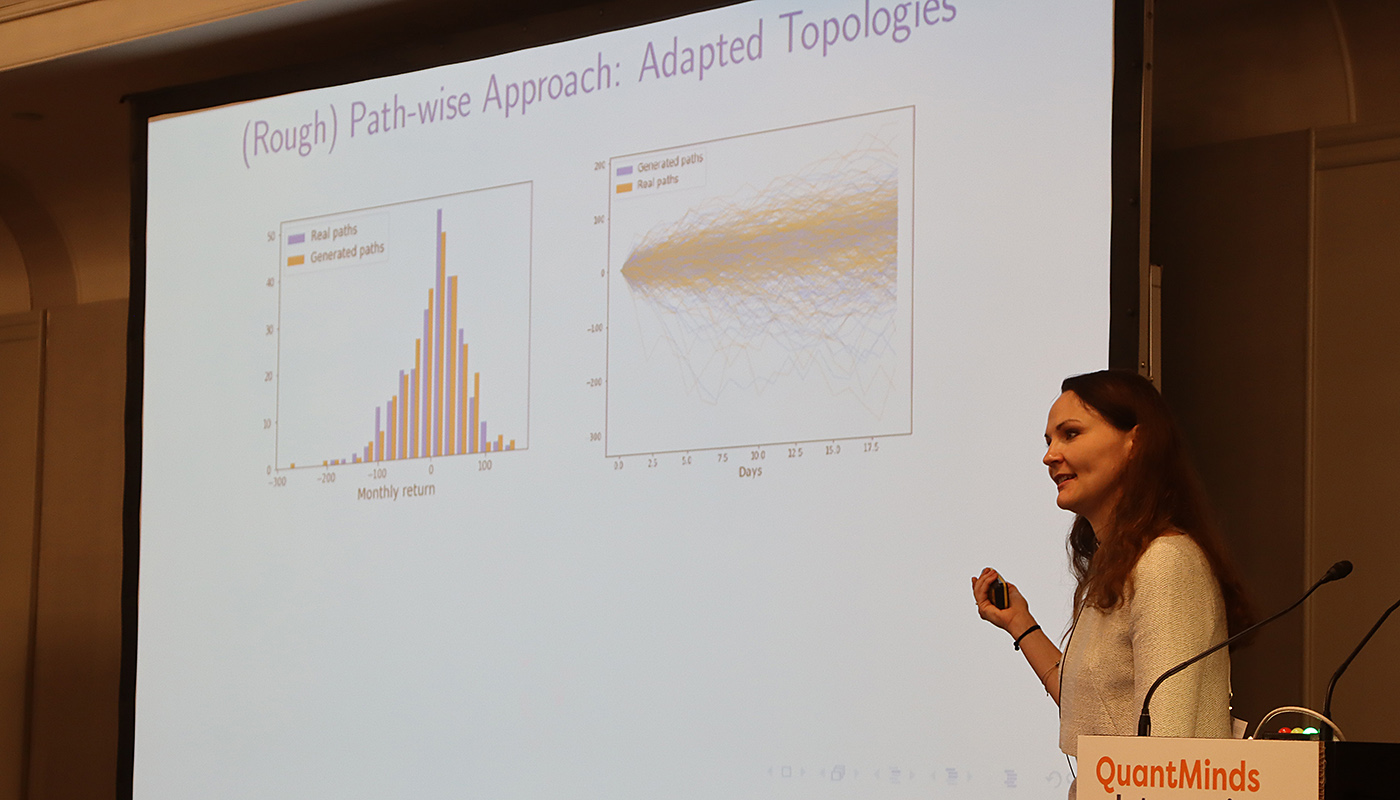
Hans Buehler kicked off the AI/ML summit day with his presentation on “Learning To Trade”, based upon papers he has co-authored (on deep hedging, as well as this paper on spot and option market simulation). The general idea was to use reinforcement learning to develop algorithms which could be used to trade, and he presented some example results showing the model’s path for hedging a cliquet option. In order to train such a model, you need large amounts of data, and hence he presented a framework for simulating the option market. Blanka Horvath elaborated on the market simulation (see this paper which includes Buehler as a coauthor), where she compared the distribution of the returns from simulations with real paths, as a way of benchmarking.
There were a number of discussions about market microstructure, including a very entertaining panel with Zoltan Eisler, Michael Steliaros, Mehdi Tomas and Fabrizio Lillo discussing topics including the market impact from the comovements of assets. The general idea is that typically when considering market impact, it is often done in isolation for a single asset. However, in practice, assets are correlated, particularly during times of risk aversion, precisely those times when liquidity is most costly.

Later Steliaros presented with his colleague at Goldman Sachs, Andreas Petrides, various results from equity market microstructure both in US and European markets. Their main point was that often algos are developed without any specific consideration about the time of day. However, the equity market trades very differently around the opening and closing auctions. They noted that whilst certain stylized observations may not be sufficiently large to generate alpha, they could be used to improve an execution algorithm. The key for execution was not only predicting the prevailing direction of the market (of course!), but also to forecast volatility and volume. They also went into more detail about the importance of considering a whole basket when executing, not purely to view assets in isolation when executing. It was also noted that the shift from active to passive ETF flows was resulting in changes in the market, which could explain some persistent behaviours like mean-reversion.

Reinforcement learning also came up in a presentation by Matteo Rolle and Daniele Rossano from Sella Financial Markets. They presented a framework that they used in production for trading, which included a module for using reinforcement learning to “discover” intraday trading strategies, a backtester, as well as a tick database, and modules for keeping track of positions when trading live. They noted that one key point with any backtester is that it needs to accurately reflect real trading conditions. Hence, they often compared backtested performance with that achieved in real trading. I’ve often done this is when I’ve run models whether on my personal account or in the past when working in banks, comparing the actual realised P&L with that the backtest calculates. They can deviate for a number of reasons such as transaction costs assumptions in the backtester. It can also be challenging to backtest trading strategies, which are trading at high frequency and giving liquidity to the market, where you might need to make certain assumptions of whether your orders would have been hit or not. They noted some of the challenges with using reinforcement learning, notably the need for large datasets, instability (which required careful tuning of hyperparameters) and that it was computationally intensive. Their solution was to use GPUs for the training process.
Quantum computing has been a subject of many talks over the years at QuantMinds. This year was no different, with a presentation from Angel Rodriguez-Rozas, from Santander, introducing the topic. He noted that classical computing architecture hasn’t really evolved, it still uses bits and logical gates. Quantum computing instead used qubits, which could be modelled like the spin of electrons, and quantum gates. The result was that certain problems could be solved much faster. The key though was that the problem needed to be remapped into a quantum form (eg. Schrodinger equation). For example a quantum Fourier transform algorithm has cost of O(n^2) whilst in the classical use case it was O(n2^n). He showed how Black-Scholes could be mapped to a quantum problem for solving.
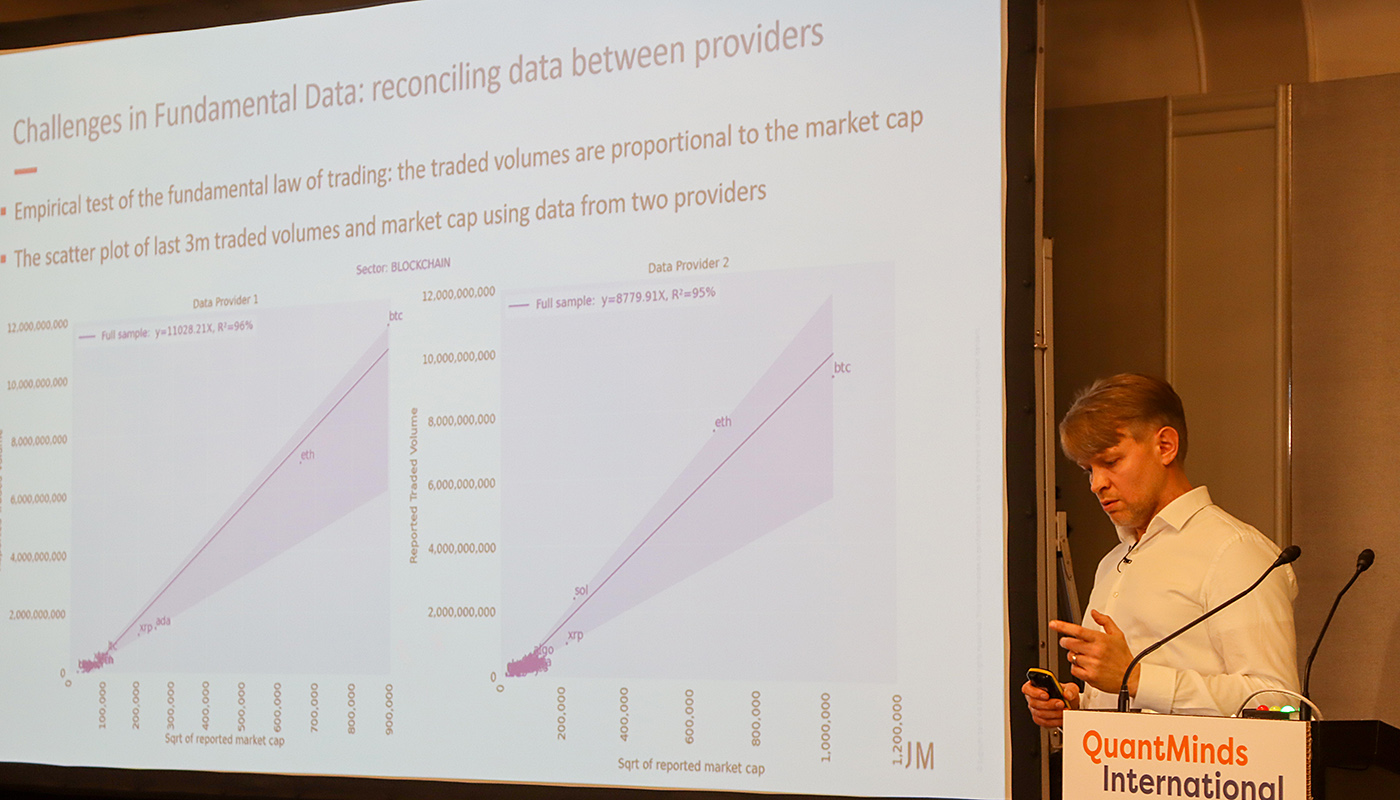
Over the years, cryptocurrency presentations have become a bigger part of the agenda at QuantMinds. This year I attended two talks on the subject given by Artur Sepp at Sygnum and another by Gurraj Sangha at Tokenmetrics. Artur Sepp presentation centred around developing systematic strategies for crypto. There are no “smart beta” indices for cryptocurrencies, unlike in traditional asset classes. There are many opportunities in cryptocurrency space, for asset managers, whether in managing index construction, providing custody and obviously to implement the execute for their trading strategies. However, there are many challenges in crypto, when it comes to implementing trading strategies. There is too little data history and the data quality is variable. Different data sources could yield very different results, making it challenging to get value from backtests. He also noted that combination of good quality fundamental data could add alpha.
Sangha’s talk centred around data available for cryptocurrencies from the blockchain. He showed the use of metrics such as total inflow/outflow, stable coin ratios and hash ratio, could be used to understand underlying price moves in crypto. He suggested that preceding drops, there was a meaningful move of bitcoin onto exchanges (presumably to liquidate). Outflows from exchanges tend to be followed by moves higher. The key takeaway that these other metrics could be an important to help model cryptocurrencies, as opposed to using purely price data in isolation.

Being able to classify market regimes is a key problem and for good reason. If I can accurately classify the current regime, it can give me a signal to turn on/off certain trading models. Aitor Murgurta Gonzalez’s presentation discussed classifying market regimes. The idea was to find a method to cluster segments of returns in a nonparameteric way, using unsupervised learning. K-means clustering is a common technique He showed how using Wasserstein distances within K-means and he noted how it tends to perform better than hidden Markov models, which is often another model used for classification of regimes.
I also spoke at QuantMinds, discussing ways of harvesting the volatility risk premium in FX options, with a particular focus on how to use Python and several libraries finmarketpy and FinancePy to backtest these strategies. Having things like Jupyter notebooks really make a big difference when presenting results, given it is so easy to show both code and results at the same time.
There were also two talks from Jon Hill. The first was entitled “Towards a New Generation of Self Referencing Smart Models”. The idea was that any model in a financial institution should broadcast when it was being used. This would provide a way to track what models were being used and how often, answering many possible regulatory questions. I think generally this seems like a good idea. Often as quants, we don’t know who is using our models/codes. Having some sort of feedback like this would allow us to understand where to concentrate our energy in maintaining/developing new models. Hill also had another presentation talking about model failures outside of finance, giving examples such as the sinking of the Vasa and numerous other thought provoking examples, which could be just as applicable today.

Initially QuantMinds was a conference that focused on derivatives pricing (it was formally called Global Derivatives) and has featured many of the best known academics and practitioners in this space including John Hull, whose popular textbook on derivatives is likely to sit on many trading floors.
These days it still very much covers derivatives pricing, but also many other facets of quantitative finance, and in many cases in recent years it has featured use cases for machine learning in finance. It was good to be back at QuantMinds in person after an absence of nearly 18 months since the last live event in Vienna. At time of press, it seems that the COVID situation is becoming more serious, so I feel somewhat lucky I was able to attend, as it seems likely in person events are likely to be curtailed in the near term. Looking forward to QuantMinds 2022! Let’s hope things return to some semblance of normality by then.